这篇博文最初由Sebastian Burgstaller为 Bitmovin 博客撰写。Bitmovin 是 OpenAPI Initiative 的成员。
不要错过今年最全面的 API 活动 ASC 2019,该活动将于 10 月 15 日至 17 日在不列颠哥伦比亚省温哥华举行。此处提供信息和注册详情。
与大多数技术产品一样,文档是客户成功的关键因素,对于 API 驱动的产品而言,这种观点更加正确,但良好的文档仅是故事的一部分。当然,我们提供了一个漂亮的仪表板,在那里绝对可以启动 编码,但我们仍然发现,在我们系统中处理的大部分编码都是通过 API 调用启动的。即使这样,最好的 API 文档也只能让你走这么远——如果没有 API SDK,你需要自己实现所有调用,然后才能享受你第一次编码的内容。这就是为什么 Bitmovin 团队始终为每个 API SDK 提供多种不同编程语言的详细文档,以便任何开发人员都可以在几分钟内启动他们的第一次编码。
保持文档和 SDK 同步绝非易事,尤其是在每周添加新功能时。我们需要一种更好的方法来连接这些部分,我们的搜索将我们引向了 OpenAPI 3.0 规范。
长话短说:在过去的一年中,我们将现有的 API Blueprint 文档迁移到 OpenAPI 格式。此迁移详细说明了 800 多个端点,因此需要大量的工程量,但正因为如此,我们不仅能够提供令人惊叹且详细的文档,还可以生成我们的 API SDK,使其与我们的完整功能集保持同步。
让我们深入了解我们旅程的细节,并展示我们在过程中取得的其他重大成果。
什么是 OpenAPI?
OpenAPI 规范(以前称为 Swagger 规范)定义了如何以机器可读的方式描述和记录 RESTful Web 服务。对我们来说,这一点至关重要,因为我们希望为客户提供美观且易于发现的文档。随着时间的推移,出现了不同的规范格式,如 RAML 或 API Blueprint,但行业越来越趋向于 OpenAPI。2015 年,OpenAPI Initiative 成立,将谷歌、微软、IBM 等多家公司的努力整合到一个框架下。这向业界发出了一个强烈的信号,表明这种文档格式即将成为事实上的标准,并且可以高度信赖地使用。从那时起,不同的公司和社区贡献了许多优秀的工具。
OpenAPI 的技术背景
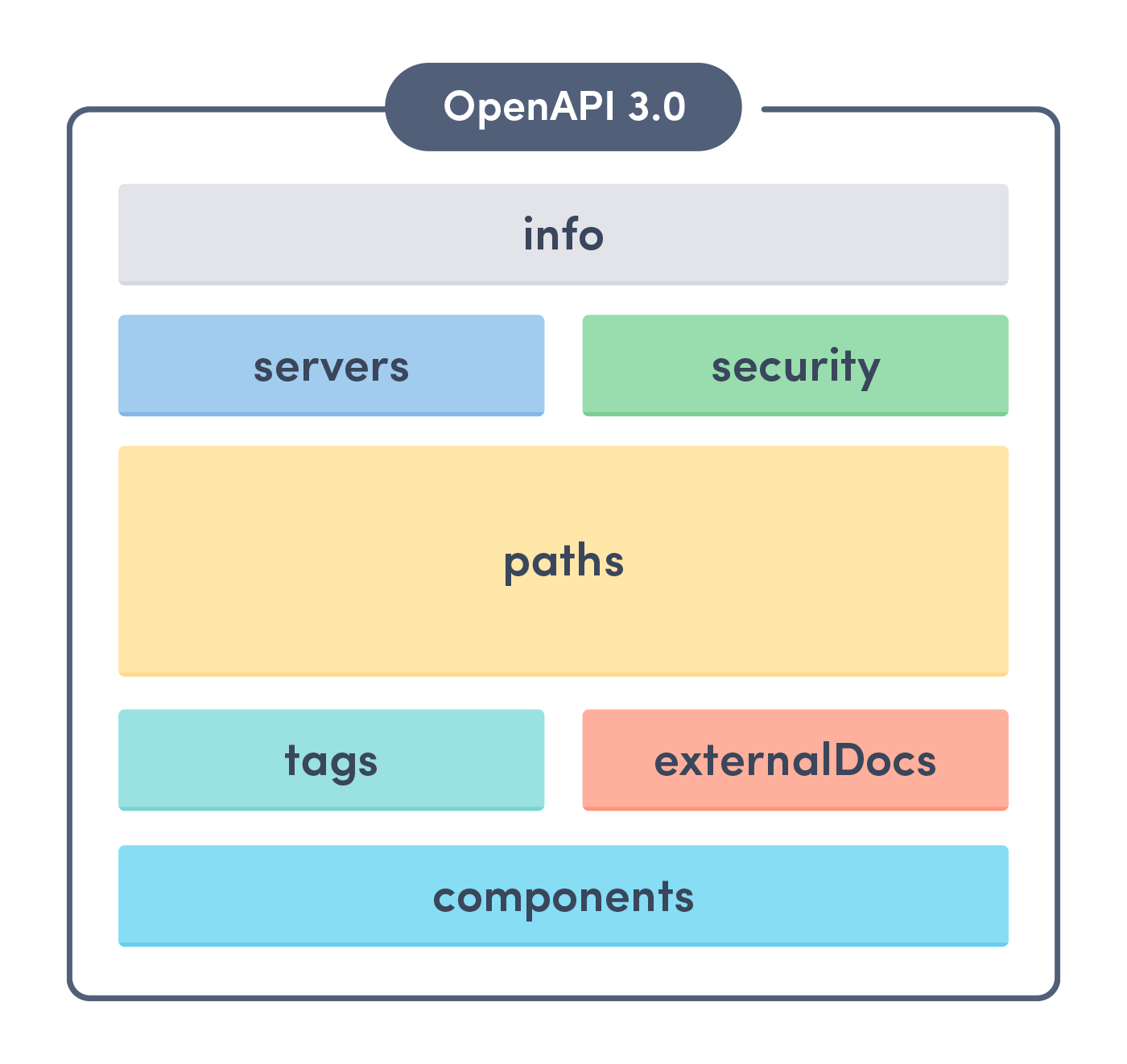
OpenAPI 文档以 JSON 或 YAML 语法编写,并结构化为以下块
对我们来说,最重要的块是 components,其中包含我们在请求和/或响应的 HTTP 主体中使用的所有模型,以及 paths,其中包含 API 提供的所有端点和操作的列表。一个简单的 OpenAPI 文档示例可以在此处找到。
那么为什么要迁移到 OpenAPI 呢?
更好的文档有助于工程团队轻松扩展并跟上要求苛刻的项目。以下是一些 Bitmovin 决定迁移到 OpenAPI 的主要原因:
1. 简化和可搜索的在线文档
凭借我们新的 API 定义,我们能够探索 OpenAPI 生态系统中面向文档的工具。这使我们找到了swagger-ui项目,该项目现在是我们在线API 参考的基础。现在,我们的文档不仅列出了我们产品的每个端点,还详细描述了它们,包括示例请求和示例响应。
我们发现,大多数技术人员更喜欢通过测试来了解新功能,这就是为什么我们允许登录用户直接从端点文档发送请求。要了解其工作原理,只需点击“试用”按钮并填写请求详细信息即可——无需输入您的 API 密钥,我们已为您配置好。没有 Bitmovin 帐户?立即注册 30 天免费试用。
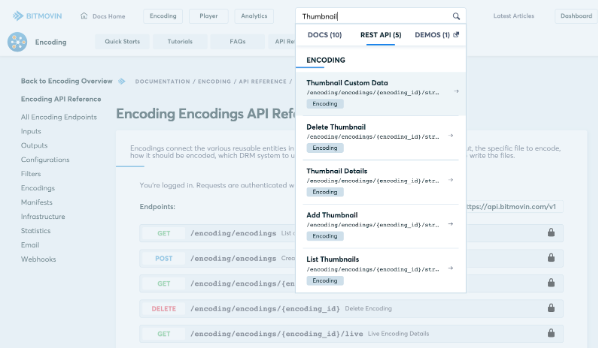
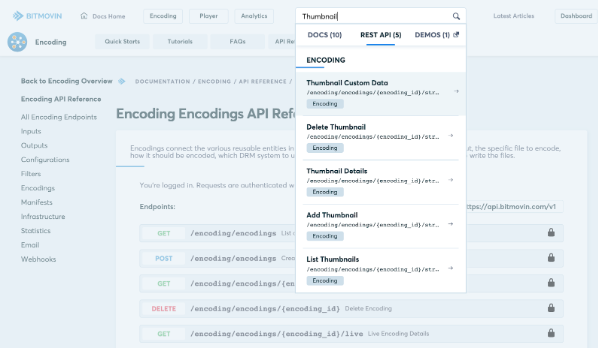
在创建文档时,不仅要提供有意义、完整和最新的信息,而且还要确保所有这些信息都易于发现和访问。这就是我们在 API 文档周围构建强大的全文搜索功能的原因。例如,想要查找用于为您的编码创建缩略图的端点?只需在顶部搜索栏中搜索“缩略图”,所有资源就会在眨眼间列出。
2. 多语言 SDK 代码生成
为了让我们的客户尽可能轻松愉快地使用我们的产品,我们提供了七种不同语言的 API SDK:Java、JavaScript、Python、Go、PHP、Ruby 和 C#。这些 SDK 受到积极的支持,但始终难以跟上产品开发的速度。添加的每个新功能都意味着它也必须在这些 SDK 代码库中实现。由于这是一个耗时(且容易出错)的过程,因此我们决定探索 SDK 代码生成的可能性。
OpenAPI 生成器是一个用 Java 编写的开源项目,可以为多种不同的语言生成 API SDK。这是通过结合特定于语言的代码和一些Mustache 模板来完成的。生成器代码定义了哪些关键字在特定语言中是保留的,或者定义了变量和方法的大小写。模板基本上是带占位符的代码片段,这些代码片段与我们的 API 定义结合在一起,将形成与 API 通信所需的 API SDK 代码。
我们评估了现有的生成器,发现它非常适合中小型 API,但对于我们的用例来说,它最终过于限制性。让我们来看一个例子:要获取在 API 中创建的特定 AWS S3 输入的详细信息,需要调用此端点
GET https://api.bitmovin.com/v1/encoding/inputs/s3/{input_id}
使用默认生成器生成 Java SDK 后,我们将能够以以下方式调用此端点
S3Input s3Input = client.getEncodingInputsS3ByInputId(inputId);
如您所见,该方法作为客户端对象的一部分生成。实际上,此单个客户端对象将包含我们所有 API 方法——我们的整个 API 表面。
我们理念的一个关键方面是,我们的客户需要能够配置编码作业的每个细节。我们提供的这种强大功能和自由自然会导致更大的 API 表面。我们不希望将所有这些方法都放在一个 API 客户端对象中,而是希望我们的 SDK 结构尽可能地与我们的 API 相似。它们应该易于探索,并清楚地表明在任何时候都会调用哪个端点。
S3Input s3Input = client.encoding.inputs.s3.get(inputId);
因此,我们决定在生成器项目之上编写我们自己的生成器逻辑和模板。端点 URL 的每个斜杠 (/) 也应该是我们 SDK 中的分隔符,这意味着每个资源的方法都在其自己的小型子 API 客户端对象中生成。这确保了我们的 SDK 用户不会被需要在任何给定时间从中选择的方法数量所淹没。它实现了我们追求的探索性 API 使用方式。
当我们开始编写我们自己的生成器代码和模板时,我们估计这将是一个相对简单的任务——毕竟,我们只想重构已经生成的代码。然而,事实证明,生成器的当前设计并不像我们计划的那样鼓励扩展。我们仍然设法将生成器项目用作基础,并且很高兴拥有它,但我们不得不投入比预期更多的时间。在完成所有这些工作之后,我们认为像 JavaScript 这样的动态类型语言可能更适合 API SDK 生成器,因为它提供了自然的自定义可能性。我们可能低估的另一个点是,为其各自的语言设计 API SDK 以使其尽可能地符合习惯用法的努力。使用 SDK 应该很有趣,并且对我们的客户来说感觉自然,但同时代码需要面向未来,鼓励添加功能而不产生破坏性更改。
3. 持续集成和交付
现在我们能够生成 API SDK 了,下一步是自动化此过程。我们现在处于一个可以为我们的文档创建新的 API 端点原型,并在几分钟内准备好一个自动生成和测试的 SDK 的状态。在此过程中,文档也会自动进行完整性检查,并执行一系列语义验证。
为了 100% 确保每个 SDK 版本都完全有效,我们创建了一套数十个存根 HTTP 调用,每个 SDK 都必须发出这些调用并在集成测试中进行验证。如果某个 SDK 未执行套件中的请求或未能正确处理响应,我们将立即停止交付过程并提醒我们的工程师出现的问题。我们使用 Wiremock 作为模拟服务器,因为它事实证明是集成到我们的自动化构建过程中的完美工具。
采用 OpenAPI 对工程团队的影响
在 Bitmovin,关于新端点设计的讨论现在集中在文档或生成的代码上。我们甚至可以编写(尚未运行但可以编译)示例工作流程,这些工作流程展示了新功能如何在其他功能的上下文中使用。一旦我们对文档满意,我们就可以开始在我们的后端服务中实现必要的更改。最后,我们通过编写端到端测试来试用我们生成的 SDK,这些测试在每晚都会启动(大量)真实的编码。所有这些步骤确保了后端服务中的一切都已正确实现,并且与我们在 API 文档中定义的内容相匹配,这是一种我们以前仅使用旧版 API 文档时从未有过的安全保障。
Bitmovin 的 OpenAPI 之旅的下一步
我们已经向公众发布了 7 个计划中的 API SDK 中的 5 个。第一个(Java)作为稳定版本可用,并且从现在开始不会经历任何重大更改。其他 SDK 将在不久的将来推出,我们很乐意接受您的想法和建议,以便我们交付尽可能好的 SDK。每个 SDK 都会附带一组示例,因此您可以快速了解如何使用新的 SDK。
我们非常高兴我们为 API 文档切换到 OpenAPI,因为这将节省我们未来很多时间,我们现在可以将这些时间投入到功能开发中。保证正确且超快速的 SDK 更新、美观且可搜索的在线文档和丰富的工具等优势,以及我们尚未开发的其他优势,都为我们的客户和我们带来了巨大的质量改进。我们渴望看看我们接下来可以用 OpenAPI 做些什么。
OpenAPI 相关链接
SDK 存储库





 关于作者
关于作者 关于作者
关于作者 关于作者
关于作者